(Bellec, et. al, 2020): eprop for Evidence Accumulation Task
Implementation of the paper:
Bellec, G., Scherr, F., Subramoney, A., Hajek, E., Salaj, D., Legenstein, R., & Maass, W. (2020). A solution to the learning dilemma for recurrent networks of spiking neurons. Nature communications, 11(1), 1-15.
[1]:
import matplotlib.pyplot as plt
import numpy as np
import brainpy as bp
import brainpy.math as bm
from jax.lax import stop_gradient
from matplotlib import patches
bm.set_environment(bm.training_mode, dt=1.)
[2]:
# training parameters
n_batch = 128 # batch size
# neuron model and simulation parameters
reg_f = 1. # regularization coefficient for firing rate
reg_rate = 10 # target firing rate for regularization [Hz]
# Experiment parameters
t_cue_spacing = 150 # distance between two consecutive cues in ms
# Frequencies
input_f0 = 40. / 1000. # poisson firing rate of input neurons in khz
regularization_f0 = reg_rate / 1000. # mean target network firing frequency
[3]:
class EligSNN(bp.Network):
def __init__(self, num_in, num_rec, num_out, eprop=True, tau_a=2e3, tau_v=2e1):
super(EligSNN, self).__init__()
# parameters
self.num_in = num_in
self.num_rec = num_rec
self.num_out = num_out
self.eprop = eprop
# neurons
self.i = bp.neurons.InputGroup(num_in)
self.o = bp.neurons.LeakyIntegrator(num_out, tau=20, mode=bm.training_mode)
n_regular = int(num_rec / 2)
n_adaptive = num_rec - n_regular
beta1 = bm.exp(- bm.get_dt() / tau_a)
beta2 = 1.7 * (1 - beta1) / (1 - bm.exp(-1 / tau_v))
beta = bm.concatenate([bm.ones(n_regular), bm.ones(n_adaptive) * beta2])
self.r = bp.neurons.ALIFBellec2020(
num_rec,
V_rest=0.,
tau_ref=5.,
V_th=0.6,
tau_a=tau_a,
tau=tau_v,
beta=beta,
V_initializer=bp.init.ZeroInit(),
a_initializer=bp.init.ZeroInit(),
mode=bm.training_mode, eprop=eprop
)
# synapses
self.i2r = bp.layers.Dense(num_in, num_rec,
W_initializer=bp.init.KaimingNormal(),
b_initializer=None)
self.i2r.W *= tau_v
self.r2r = bp.layers.Dense(num_rec, num_rec,
W_initializer=bp.init.KaimingNormal(),
b_initializer=None)
self.r2r.W *= tau_v
self.r2o = bp.layers.Dense(num_rec, num_out,
W_initializer=bp.init.KaimingNormal(),
b_initializer=None)
def update(self, shared, x):
self.r.input += self.i2r(shared, x)
z = stop_gradient(self.r.spike.value) if self.eprop else self.r.spike.value
self.r.input += self.r2r(shared, z)
self.r(shared)
self.o.input += self.r2o(shared, self.r.spike.value)
self.o(shared)
return self.o.V.value
[4]:
net = EligSNN(num_in=40, num_rec=100, num_out=2, eprop=False)
WARNING:jax._src.lib.xla_bridge:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
[5]:
@bp.tools.numba_jit
def generate_click_task_data(batch_size, seq_len, n_neuron, recall_duration, prob, f0=0.5,
n_cues=7, t_cue=100, t_interval=150, n_input_symbols=4):
n_channel = n_neuron // n_input_symbols
# assign input spike probabilities
probs = np.where(np.random.random((batch_size, 1)) < 0.5, prob, 1 - prob)
# for each example in batch, draw which cues are going to be active (left or right)
cue_assignments = np.asarray(np.random.random(n_cues) > probs, dtype=np.int_)
# generate input nums - 0: left, 1: right, 2:recall, 3:background noise
input_nums = 3 * np.ones((batch_size, seq_len), dtype=np.int_)
input_nums[:, :n_cues] = cue_assignments
input_nums[:, -1] = 2
# generate input spikes
input_spike_prob = np.zeros((batch_size, seq_len, n_neuron))
d_silence = t_interval - t_cue
for b in range(batch_size):
for k in range(n_cues):
# input channels only fire when they are selected (left or right)
c = cue_assignments[b, k]
# reverse order of cues
i_seq = d_silence + k * t_interval
i_neu = c * n_channel
input_spike_prob[b, i_seq:i_seq + t_cue, i_neu:i_neu + n_channel] = f0
# recall cue
input_spike_prob[:, -recall_duration:, 2 * n_channel:3 * n_channel] = f0
# background noise
input_spike_prob[:, :, 3 * n_channel:] = f0 / 4.
input_spikes = input_spike_prob > np.random.rand(*input_spike_prob.shape)
# generate targets
target_mask = np.zeros((batch_size, seq_len), dtype=np.bool_)
target_mask[:, -1] = True
target_nums = (np.sum(cue_assignments, axis=1) > n_cues / 2).astype(np.int_)
return input_spikes, input_nums, target_nums, target_mask
[6]:
def get_data(batch_size, n_in, t_interval, f0):
# used for obtaining a new randomly generated batch of examples
def generate_data():
seq_len = int(t_interval * 7 + 1200)
for _ in range(10):
spk_data, _, target_data, _ = generate_click_task_data(
batch_size=batch_size, seq_len=seq_len, n_neuron=n_in, recall_duration=150,
prob=0.3, t_cue=100, n_cues=7, t_interval=t_interval, f0=f0, n_input_symbols=4
)
yield spk_data, target_data
return generate_data
[7]:
def loss_fun(predicts, targets):
predicts, mon = predicts
# we only use network output at the end for classification
output_logits = predicts[:, -t_cue_spacing:]
# Define the accuracy
y_predict = bm.argmax(bm.mean(output_logits, axis=1), axis=1)
accuracy = bm.equal(targets, y_predict).astype(bm.dftype()).mean()
# loss function
tiled_targets = bm.tile(bm.expand_dims(targets, 1), (1, t_cue_spacing))
loss_cls = bm.mean(bp.losses.cross_entropy_loss(output_logits, tiled_targets))
# Firing rate regularization:
# For historical reason we often use this regularization,
# but the other one is easier to implement in an "online" fashion by a single agent.
av = bm.mean(mon['r.spike'], axis=(0, 1)) / bm.get_dt()
loss_reg_f = bm.sum(bm.square(av - regularization_f0) * reg_f)
# Aggregate the losses #
loss = loss_reg_f + loss_cls
loss_res = {'loss': loss, 'loss reg': loss_reg_f, 'accuracy': accuracy}
return bm.as_jax(loss), loss_res
Training
[8]:
# Training
trainer = bp.BPTT(
net,
loss_fun,
loss_has_aux=True,
optimizer=bp.optim.Adam(lr=0.01),
monitors={'r.spike': net.r.spike},
)
trainer.fit(get_data(n_batch, n_in=net.num_in, t_interval=t_cue_spacing, f0=input_f0),
num_epoch=40,
num_report=10)
Train 10 steps, use 9.8286 s, loss 0.7034175992012024, accuracy 0.4281249940395355, loss reg 0.004963034763932228
Train 20 steps, use 7.3619 s, loss 0.7023941874504089, accuracy 0.4046874940395355, loss reg 0.004842016380280256
Train 30 steps, use 7.3519 s, loss 0.6943514943122864, accuracy 0.596875011920929, loss reg 0.004735519178211689
Train 40 steps, use 7.3225 s, loss 0.6893576383590698, accuracy 0.5882812738418579, loss reg 0.004621113184839487
Train 50 steps, use 7.4316 s, loss 0.7021943926811218, accuracy 0.45703125, loss reg 0.0045189810916781425
Train 60 steps, use 7.3455 s, loss 0.7054350972175598, accuracy 0.3843750059604645, loss reg 0.004483774304389954
Train 70 steps, use 7.5527 s, loss 0.6898735761642456, accuracy 0.56640625, loss reg 0.0044373138807713985
Train 80 steps, use 7.3871 s, loss 0.69098299741745, accuracy 0.5992187857627869, loss reg 0.004469707142561674
Train 90 steps, use 7.3317 s, loss 0.6886122822761536, accuracy 0.6968750357627869, loss reg 0.004408594686537981
Train 100 steps, use 7.4113 s, loss 0.6826426386833191, accuracy 0.749218761920929, loss reg 0.004439009819179773
Train 110 steps, use 7.4938 s, loss 0.6881702542304993, accuracy 0.633593738079071, loss reg 0.004656294826418161
Train 120 steps, use 7.2987 s, loss 0.6720143556594849, accuracy 0.772656261920929, loss reg 0.004621779080480337
Train 130 steps, use 7.4011 s, loss 0.6499411463737488, accuracy 0.8023437857627869, loss reg 0.004800095688551664
Train 140 steps, use 7.3568 s, loss 0.6571835875511169, accuracy 0.710156261920929, loss reg 0.005033737048506737
Train 150 steps, use 7.1787 s, loss 0.6523110866546631, accuracy 0.7250000238418579, loss reg 0.00559642817825079
Train 160 steps, use 7.1760 s, loss 0.608909010887146, accuracy 0.821093738079071, loss reg 0.005754651036113501
Train 170 steps, use 7.2558 s, loss 0.5620784163475037, accuracy 0.844531238079071, loss reg 0.006214872468262911
Train 180 steps, use 7.2844 s, loss 0.5986811518669128, accuracy 0.750781238079071, loss reg 0.006925530731678009
Train 190 steps, use 7.4182 s, loss 0.544775664806366, accuracy 0.848437488079071, loss reg 0.006775358226150274
Train 200 steps, use 7.4347 s, loss 0.5496039390563965, accuracy 0.831250011920929, loss reg 0.007397319655865431
Train 210 steps, use 7.4629 s, loss 0.5447431206703186, accuracy 0.813281238079071, loss reg 0.006942986976355314
Train 220 steps, use 7.3833 s, loss 0.5015143752098083, accuracy 0.85546875, loss reg 0.0072592394426465034
Train 230 steps, use 7.4328 s, loss 0.5421426296234131, accuracy 0.854687511920929, loss reg 0.0077950432896614075
Train 240 steps, use 7.4438 s, loss 0.4893417954444885, accuracy 0.875781238079071, loss reg 0.007711453828960657
Train 250 steps, use 7.3671 s, loss 0.48076897859573364, accuracy 0.8203125, loss reg 0.006535724736750126
Train 260 steps, use 7.3650 s, loss 0.46686863899230957, accuracy 0.8617187738418579, loss reg 0.007533709984272718
Train 270 steps, use 7.4364 s, loss 0.4155255854129791, accuracy 0.9156250357627869, loss reg 0.007653679233044386
Train 280 steps, use 7.5231 s, loss 0.5252839922904968, accuracy 0.8070312738418579, loss reg 0.0074622235260903835
Train 290 steps, use 7.4474 s, loss 0.4552551209926605, accuracy 0.840624988079071, loss reg 0.007330414839088917
Train 300 steps, use 7.3283 s, loss 0.4508514404296875, accuracy 0.8617187738418579, loss reg 0.007133393082767725
Train 310 steps, use 7.3453 s, loss 0.38369470834732056, accuracy 0.925000011920929, loss reg 0.007317659445106983
Train 320 steps, use 7.2690 s, loss 0.4067922532558441, accuracy 0.9125000238418579, loss reg 0.00806522835046053
Train 330 steps, use 7.4205 s, loss 0.4162019193172455, accuracy 0.8843750357627869, loss reg 0.0077808513306081295
Train 340 steps, use 7.3557 s, loss 0.42762160301208496, accuracy 0.8695312738418579, loss reg 0.00763324648141861
Train 350 steps, use 7.4115 s, loss 0.38524919748306274, accuracy 0.8984375, loss reg 0.00784334447234869
Train 360 steps, use 7.3625 s, loss 0.36755821108818054, accuracy 0.905468761920929, loss reg 0.007520874030888081
Train 370 steps, use 7.3553 s, loss 0.4653354585170746, accuracy 0.839062511920929, loss reg 0.007807845715433359
Train 380 steps, use 7.4220 s, loss 0.46386781334877014, accuracy 0.828906238079071, loss reg 0.007937172427773476
Train 390 steps, use 7.3668 s, loss 0.5748793482780457, accuracy 0.75, loss reg 0.007791445590555668
Train 400 steps, use 7.2759 s, loss 0.3976801037788391, accuracy 0.8812500238418579, loss reg 0.007725016679614782
Visualization
[9]:
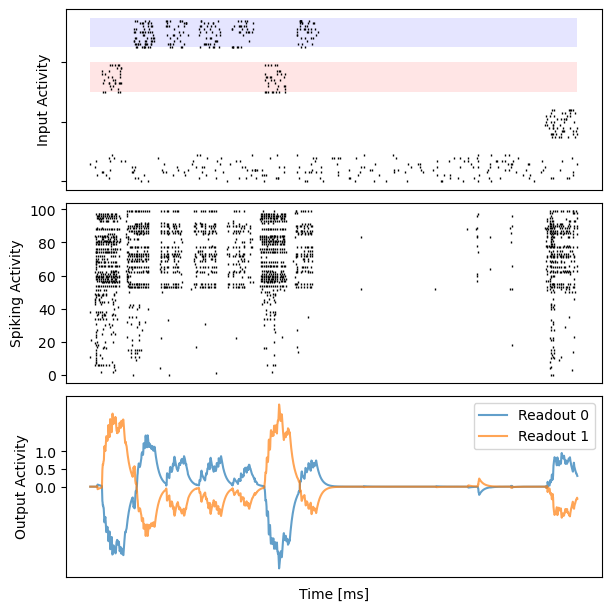
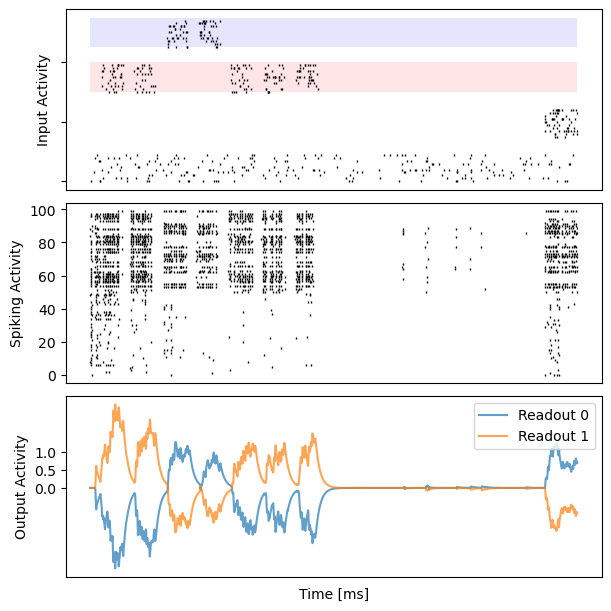
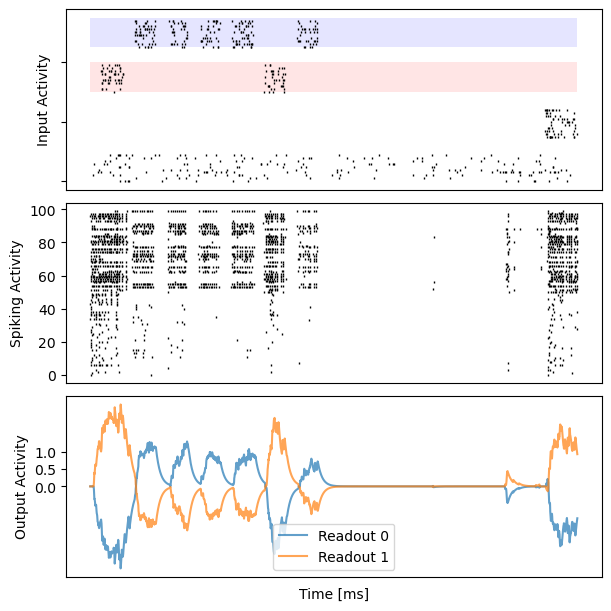
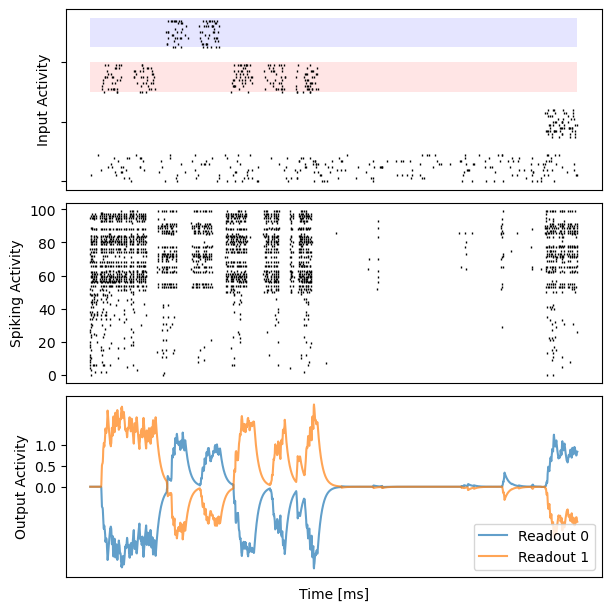
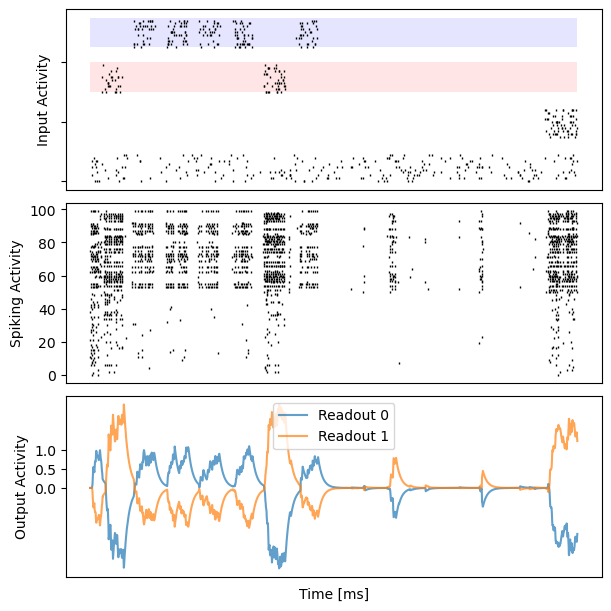
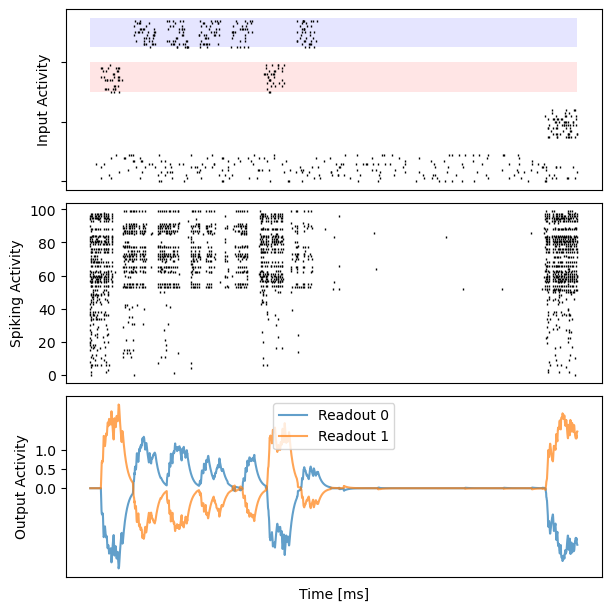
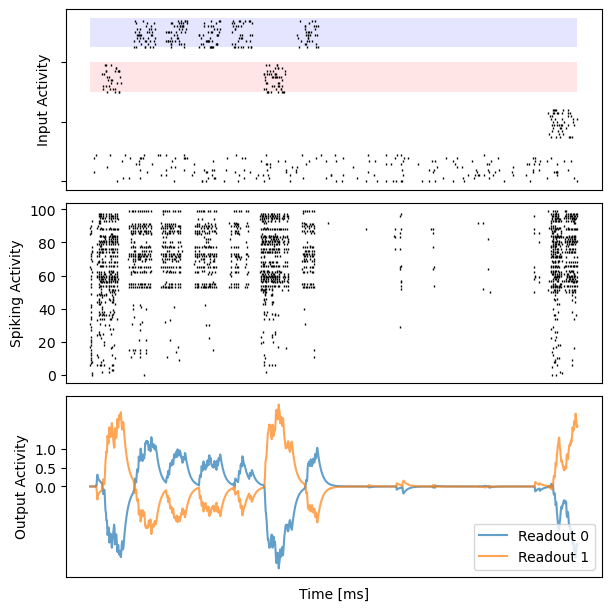
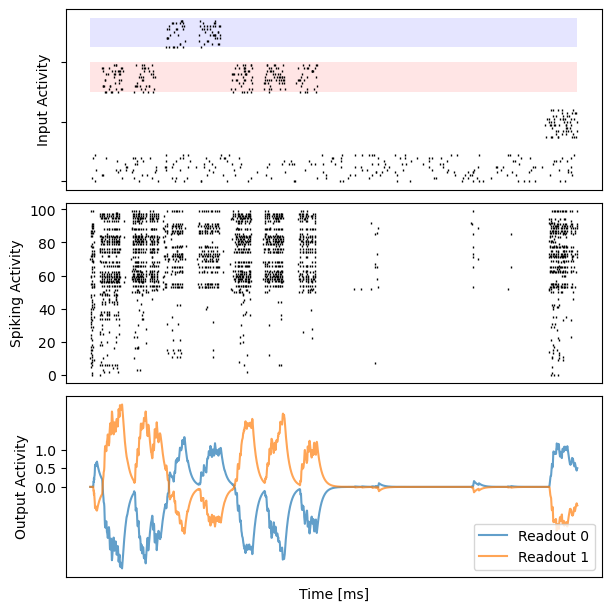
# visualization
dataset, _ = next(get_data(20, n_in=net.num_in, t_interval=t_cue_spacing, f0=input_f0)())
runner = bp.DSTrainer(net, monitors={'spike': net.r.spike})
outs = runner.predict(dataset, reset_state=True)
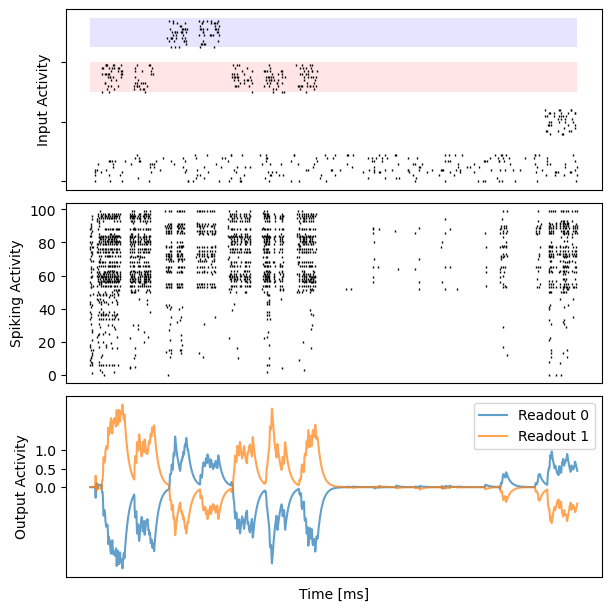
for i in range(10):
fig, gs = bp.visualize.get_figure(3, 1, 2., 6.)
ax_inp = fig.add_subplot(gs[0, 0])
ax_rec = fig.add_subplot(gs[1, 0])
ax_out = fig.add_subplot(gs[2, 0])
data = dataset[i]
# insert empty row
n_channel = data.shape[1] // 4
zero_fill = np.zeros((data.shape[0], int(n_channel / 2)))
data = np.concatenate((data[:, 3 * n_channel:], zero_fill,
data[:, 2 * n_channel:3 * n_channel], zero_fill,
data[:, :n_channel], zero_fill,
data[:, n_channel:2 * n_channel]), axis=1)
ax_inp.set_yticklabels([])
ax_inp.add_patch(patches.Rectangle((0, 2 * n_channel + 2 * int(n_channel / 2)),
data.shape[0], n_channel,
facecolor="red", alpha=0.1))
ax_inp.add_patch(patches.Rectangle((0, 3 * n_channel + 3 * int(n_channel / 2)),
data.shape[0], n_channel,
facecolor="blue", alpha=0.1))
bp.visualize.raster_plot(runner.mon.ts, data, ax=ax_inp, marker='|')
ax_inp.set_ylabel('Input Activity')
ax_inp.set_xticklabels([])
ax_inp.set_xticks([])
# spiking activity
bp.visualize.raster_plot(runner.mon.ts, runner.mon['spike'][i], ax=ax_rec, marker='|')
ax_rec.set_ylabel('Spiking Activity')
ax_rec.set_xticklabels([])
ax_rec.set_xticks([])
# decision activity
ax_out.set_yticks([0, 0.5, 1])
ax_out.set_ylabel('Output Activity')
ax_out.plot(runner.mon.ts, outs[i, :, 0], label='Readout 0', alpha=0.7)
ax_out.plot(runner.mon.ts, outs[i, :, 1], label='Readout 1', alpha=0.7)
ax_out.set_xticklabels([])
ax_out.set_xticks([])
ax_out.set_xlabel('Time [ms]')
plt.legend()
plt.show()