Gap junction-coupled FitzHugh-Nagumo Model
[1]:
import brainpy as bp
import brainpy.math as bm
bp.math.enable_x64()
bp.math.set_platform('cpu')
[2]:
import numpy as np
import matplotlib.pyplot as plt
[10]:
class GJCoupledFHN(bp.dyn.DynamicalSystem):
def __init__(self, num=2, method='exp_auto'):
super(GJCoupledFHN, self).__init__()
# parameters
self.num = num
self.a = 0.7
self.b = 0.8
self.tau = 12.5
self.gjw = 0.0001
# variables
self.V = bm.Variable(bm.random.uniform(-2, 2, num))
self.w = bm.Variable(bm.random.uniform(-2, 2, num))
self.Iext = bm.Variable(bm.zeros(num))
# functions
self.int_V = bp.odeint(self.dV, method=method)
self.int_w = bp.odeint(self.dw, method=method)
def dV(self, V, t, w, Iext=0.):
gj = (V.reshape((-1, 1)) - V).sum(axis=0) * self.gjw
dV = V - V * V * V / 3 - w + Iext + gj
return dV
def dw(self, w, t, V):
dw = (V + self.a - self.b * w) / self.tau
return dw
def update(self, _t, _dt):
self.V.value = self.int_V(self.V, _t, self.w, self.Iext, _dt)
self.w.value = self.int_w(self.w, _t, self.V, _dt)
def step(self, vw):
v, w = bm.split(vw, 2)
dv = self.dV(v, 0., w, self.Iext)
dw = self.dw(w, 0., v)
return bm.concatenate([dv, dw])
[18]:
def analyze_net(num=2, gjw=0.01, Iext=bm.asarray([0., 0.6])):
assert isinstance(Iext, (int, float)) or (len(Iext) == num)
model = GJCoupledFHN(num)
model.gjw = gjw
model.Iext[:] = Iext
# simulation
runner = bp.dyn.DSRunner(model, monitors=['V'])
runner.run(300.)
bp.visualize.line_plot(runner.mon.ts, runner.mon.V, legend='V',
plot_ids=list(range(model.num)), show=True)
# analysis
finder = bp.analysis.SlowPointFinder(f_cell=model.step)
finder.find_fps_with_gd_method(
candidates=bm.random.normal(0., 2., (1000, model.num * 2)),
tolerance=1e-5, num_batch=200,
optimizer=bp.optim.Adam(lr=bp.optim.ExponentialDecay(0.05, 1, 0.9999)),
)
finder.filter_loss(1e-7)
finder.keep_unique()
print('fixed_points: ', finder.fixed_points)
print('losses:', finder.losses)
if len(finder.fixed_points):
jac = finder.compute_jacobians(finder.fixed_points)
for i in range(len(finder.fixed_points)):
eigval, eigvec = np.linalg.eig(np.asarray(jac[i]))
plt.figure()
plt.scatter(np.real(eigval), np.imag(eigval))
plt.plot([0, 0], [-1, 1], '--')
plt.xlabel('Real')
plt.ylabel('Imaginary')
plt.title(f'FP {i}')
plt.show()
4D system
[12]:
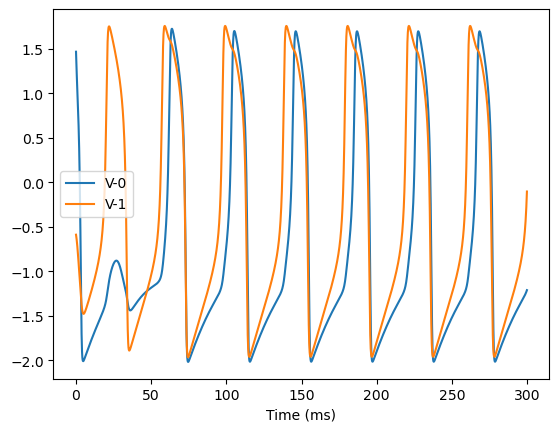
analyze_net(num=2, gjw=0.1, Iext=bm.asarray([0., 0.6]))
Optimizing to find fixed points:
Batches 1-200 in 0.26 sec, Training loss 0.1732008333
Batches 201-400 in 0.27 sec, Training loss 0.0279936077
Batches 401-600 in 0.29 sec, Training loss 0.0138208361
Batches 601-800 in 0.27 sec, Training loss 0.0106248316
Batches 801-1000 in 0.26 sec, Training loss 0.0091556911
Batches 1001-1200 in 0.26 sec, Training loss 0.0081304573
Batches 1201-1400 in 0.27 sec, Training loss 0.0073151766
Batches 1401-1600 in 0.27 sec, Training loss 0.0066392938
Batches 1601-1800 in 0.26 sec, Training loss 0.0060650256
Batches 1801-2000 in 0.26 sec, Training loss 0.0055699468
Batches 2001-2200 in 0.33 sec, Training loss 0.0051349353
Batches 2201-2400 in 0.26 sec, Training loss 0.0047495742
Batches 2401-2600 in 0.27 sec, Training loss 0.0044025139
Batches 2601-2800 in 0.26 sec, Training loss 0.0040867868
Batches 2801-3000 in 0.28 sec, Training loss 0.0037980253
Batches 3001-3200 in 0.26 sec, Training loss 0.0035305708
Batches 3201-3400 in 0.26 sec, Training loss 0.0032818752
Batches 3401-3600 in 0.27 sec, Training loss 0.0030503689
Batches 3601-3800 in 0.27 sec, Training loss 0.0028345042
Batches 3801-4000 in 0.26 sec, Training loss 0.0026316342
Batches 4001-4200 in 0.26 sec, Training loss 0.0024413986
Batches 4201-4400 in 0.26 sec, Training loss 0.0022628187
Batches 4401-4600 in 0.26 sec, Training loss 0.0020949674
Batches 4601-4800 in 0.27 sec, Training loss 0.0019376765
Batches 4801-5000 in 0.27 sec, Training loss 0.0017906726
Batches 5001-5200 in 0.26 sec, Training loss 0.0016531560
Batches 5201-5400 in 0.34 sec, Training loss 0.0015249244
Batches 5401-5600 in 0.26 sec, Training loss 0.0014050786
Batches 5601-5800 in 0.26 sec, Training loss 0.0012933069
Batches 5801-6000 in 0.26 sec, Training loss 0.0011897692
Batches 6001-6200 in 0.26 sec, Training loss 0.0010942124
Batches 6201-6400 in 0.26 sec, Training loss 0.0010058900
Batches 6401-6600 in 0.26 sec, Training loss 0.0009240781
Batches 6601-6800 in 0.27 sec, Training loss 0.0008482566
Batches 6801-7000 in 0.27 sec, Training loss 0.0007784118
Batches 7001-7200 in 0.28 sec, Training loss 0.0007137671
Batches 7201-7400 in 0.26 sec, Training loss 0.0006537358
Batches 7401-7600 in 0.26 sec, Training loss 0.0005981633
Batches 7601-7800 in 0.26 sec, Training loss 0.0005468425
Batches 7801-8000 in 0.28 sec, Training loss 0.0004996600
Batches 8001-8200 in 0.26 sec, Training loss 0.0004560033
Batches 8201-8400 in 0.27 sec, Training loss 0.0004155798
Batches 8401-8600 in 0.26 sec, Training loss 0.0003782298
Batches 8601-8800 in 0.34 sec, Training loss 0.0003438454
Batches 8801-9000 in 0.27 sec, Training loss 0.0003122042
Batches 9001-9200 in 0.27 sec, Training loss 0.0002828889
Batches 9201-9400 in 0.27 sec, Training loss 0.0002561023
Batches 9401-9600 in 0.26 sec, Training loss 0.0002318818
Batches 9601-9800 in 0.27 sec, Training loss 0.0002099542
Batches 9801-10000 in 0.27 sec, Training loss 0.0001901693
Excluding fixed points with squared speed above tolerance 0.00000:
Kept 751/1000 fixed points with tolerance under 1e-07.
Excluding non-unique fixed points:
Kept 1/751 unique fixed points with uniqueness tolerance 0.025.
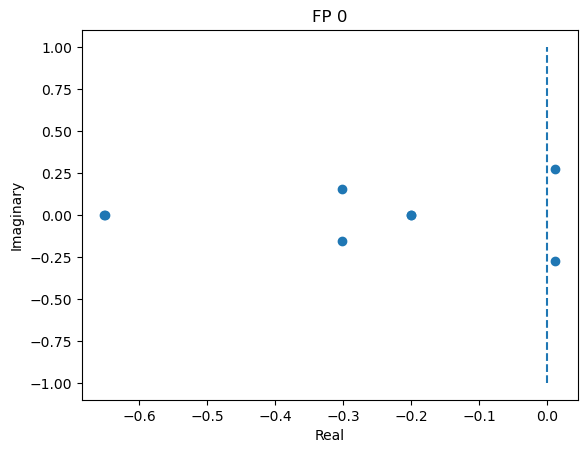
fixed_points: [[-1.1731534 -0.7380368 -0.59144206 -0.04754607]]
losses: [3.20594405e-14]
[13]:
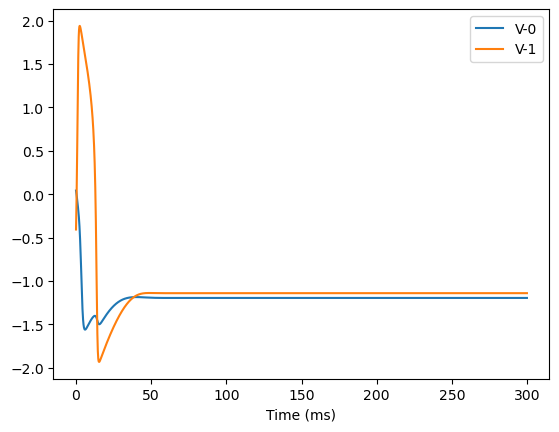
analyze_net(num=2, gjw=0.1, Iext=bm.asarray([0., 0.1]))
Optimizing to find fixed points:
Batches 1-200 in 0.28 sec, Training loss 0.1000278069
Batches 201-400 in 0.26 sec, Training loss 0.0216853047
Batches 401-600 in 0.27 sec, Training loss 0.0129203812
Batches 601-800 in 0.27 sec, Training loss 0.0103963392
Batches 801-1000 in 0.26 sec, Training loss 0.0090740372
Batches 1001-1200 in 0.26 sec, Training loss 0.0081228933
Batches 1201-1400 in 0.27 sec, Training loss 0.0073540754
Batches 1401-1600 in 0.26 sec, Training loss 0.0067063364
Batches 1601-1800 in 0.27 sec, Training loss 0.0061526375
Batches 1801-2000 in 0.27 sec, Training loss 0.0056660681
Batches 2001-2200 in 0.29 sec, Training loss 0.0052328892
Batches 2201-2400 in 0.26 sec, Training loss 0.0048409461
Batches 2401-2600 in 0.27 sec, Training loss 0.0044802725
Batches 2601-2800 in 0.27 sec, Training loss 0.0041462450
Batches 2801-3000 in 0.26 sec, Training loss 0.0038397347
Batches 3001-3200 in 0.26 sec, Training loss 0.0035571301
Batches 3201-3400 in 0.26 sec, Training loss 0.0032959649
Batches 3401-3600 in 0.26 sec, Training loss 0.0030531034
Batches 3601-3800 in 0.27 sec, Training loss 0.0028256267
Batches 3801-4000 in 0.27 sec, Training loss 0.0026102958
Batches 4001-4200 in 0.27 sec, Training loss 0.0024091971
Batches 4201-4400 in 0.37 sec, Training loss 0.0022222809
Batches 4401-4600 in 0.26 sec, Training loss 0.0020492798
Batches 4601-4800 in 0.26 sec, Training loss 0.0018891889
Batches 4801-5000 in 0.27 sec, Training loss 0.0017400522
Batches 5001-5200 in 0.27 sec, Training loss 0.0016006068
Batches 5201-5400 in 0.27 sec, Training loss 0.0014719806
Batches 5401-5600 in 0.27 sec, Training loss 0.0013526007
Batches 5601-5800 in 0.26 sec, Training loss 0.0012428929
Batches 5801-6000 in 0.26 sec, Training loss 0.0011415471
Batches 6001-6200 in 0.26 sec, Training loss 0.0010474442
Batches 6201-6400 in 0.28 sec, Training loss 0.0009602128
Batches 6401-6600 in 0.27 sec, Training loss 0.0008800711
Batches 6601-6800 in 0.27 sec, Training loss 0.0008068783
Batches 6801-7000 in 0.27 sec, Training loss 0.0007393606
Batches 7001-7200 in 0.27 sec, Training loss 0.0006771316
Batches 7201-7400 in 0.27 sec, Training loss 0.0006204218
Batches 7401-7600 in 0.27 sec, Training loss 0.0005683892
Batches 7601-7800 in 0.27 sec, Training loss 0.0005203659
Batches 7801-8000 in 0.27 sec, Training loss 0.0004759495
Batches 8001-8200 in 0.26 sec, Training loss 0.0004349670
Batches 8201-8400 in 0.27 sec, Training loss 0.0003973204
Batches 8401-8600 in 0.27 sec, Training loss 0.0003631554
Batches 8601-8800 in 0.26 sec, Training loss 0.0003319971
Batches 8801-9000 in 0.27 sec, Training loss 0.0003032476
Batches 9001-9200 in 0.27 sec, Training loss 0.0002768509
Batches 9201-9400 in 0.26 sec, Training loss 0.0002528131
Batches 9401-9600 in 0.27 sec, Training loss 0.0002308988
Batches 9601-9800 in 0.27 sec, Training loss 0.0002109862
Batches 9801-10000 in 0.27 sec, Training loss 0.0001931224
Excluding fixed points with squared speed above tolerance 0.00000:
Kept 803/1000 fixed points with tolerance under 1e-07.
Excluding non-unique fixed points:
Kept 1/803 unique fixed points with uniqueness tolerance 0.025.
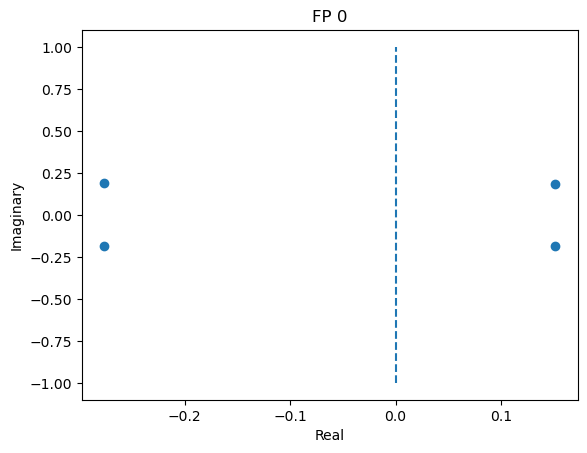
fixed_points: [[-1.19613916 -1.14106972 -0.62017396 -0.55133715]]
losses: [3.68199075e-32]
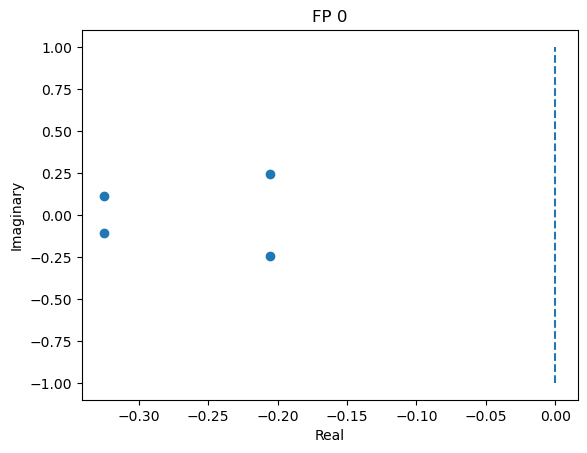
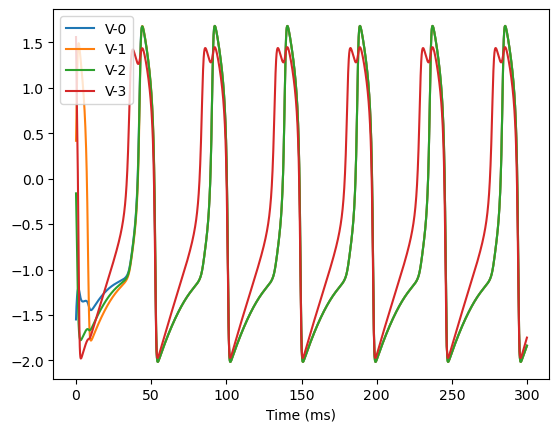
8D system
[19]:
analyze_net(num=4, gjw=0.1, Iext=bm.asarray([0., 0., 0., 0.6]))
Optimizing to find fixed points:
Batches 1-200 in 0.32 sec, Training loss 0.1248303929
Batches 201-400 in 0.32 sec, Training loss 0.0239558379
Batches 401-600 in 0.31 sec, Training loss 0.0135697149
Batches 601-800 in 0.32 sec, Training loss 0.0106228349
Batches 801-1000 in 0.32 sec, Training loss 0.0091001508
Batches 1001-1200 in 0.32 sec, Training loss 0.0080552608
Batches 1201-1400 in 0.32 sec, Training loss 0.0072481540
Batches 1401-1600 in 0.33 sec, Training loss 0.0065882325
Batches 1601-1800 in 0.32 sec, Training loss 0.0060318719
Batches 1801-2000 in 0.31 sec, Training loss 0.0055537606
Batches 2001-2200 in 0.32 sec, Training loss 0.0051327216
Batches 2201-2400 in 0.34 sec, Training loss 0.0047544718
Batches 2401-2600 in 0.32 sec, Training loss 0.0044122167
Batches 2601-2800 in 0.38 sec, Training loss 0.0041000219
Batches 2801-3000 in 0.47 sec, Training loss 0.0038109057
Batches 3001-3200 in 0.33 sec, Training loss 0.0035417694
Batches 3201-3400 in 0.31 sec, Training loss 0.0032898551
Batches 3401-3600 in 0.32 sec, Training loss 0.0030546956
Batches 3601-3800 in 0.32 sec, Training loss 0.0028352522
Batches 3801-4000 in 0.31 sec, Training loss 0.0026300925
Batches 4001-4200 in 0.31 sec, Training loss 0.0024384573
Batches 4201-4400 in 0.31 sec, Training loss 0.0022591977
Batches 4401-4600 in 0.32 sec, Training loss 0.0020917700
Batches 4601-4800 in 0.32 sec, Training loss 0.0019354556
Batches 4801-5000 in 0.31 sec, Training loss 0.0017890583
Batches 5001-5200 in 0.31 sec, Training loss 0.0016520999
Batches 5201-5400 in 0.31 sec, Training loss 0.0015240019
Batches 5401-5600 in 0.32 sec, Training loss 0.0014042815
Batches 5601-5800 in 0.31 sec, Training loss 0.0012925581
Batches 5801-6000 in 0.32 sec, Training loss 0.0011885980
Batches 6001-6200 in 0.31 sec, Training loss 0.0010920670
Batches 6201-6400 in 0.48 sec, Training loss 0.0010025192
Batches 6401-6600 in 0.34 sec, Training loss 0.0009196620
Batches 6601-6800 in 0.39 sec, Training loss 0.0008431175
Batches 6801-7000 in 0.36 sec, Training loss 0.0007723694
Batches 7001-7200 in 0.32 sec, Training loss 0.0007068438
Batches 7201-7400 in 0.31 sec, Training loss 0.0006460327
Batches 7401-7600 in 0.32 sec, Training loss 0.0005897513
Batches 7601-7800 in 0.32 sec, Training loss 0.0005379441
Batches 7801-8000 in 0.32 sec, Training loss 0.0004902647
Batches 8001-8200 in 0.31 sec, Training loss 0.0004462979
Batches 8201-8400 in 0.34 sec, Training loss 0.0004060505
Batches 8401-8600 in 0.36 sec, Training loss 0.0003694030
Batches 8601-8800 in 0.39 sec, Training loss 0.0003360897
Batches 8801-9000 in 0.37 sec, Training loss 0.0003056261
Batches 9001-9200 in 0.33 sec, Training loss 0.0002779101
Batches 9201-9400 in 0.32 sec, Training loss 0.0002526623
Batches 9401-9600 in 0.33 sec, Training loss 0.0002297107
Batches 9601-9800 in 0.31 sec, Training loss 0.0002089298
Batches 9801-10000 in 0.33 sec, Training loss 0.0001900785
Excluding fixed points with squared speed above tolerance 0.00000:
Kept 645/1000 fixed points with tolerance under 1e-07.
Excluding non-unique fixed points:
Kept 1/645 unique fixed points with uniqueness tolerance 0.025.
fixed_points: [[-1.17756259 -1.17782851 -1.17743352 -0.81460059 -0.59694415 -0.59711431
-0.596828 -0.14335882]]
losses: [2.30617396e-08]